Case_studies_2
Networks in networks & 1x1 Convolutions
It seems as just multiplying by number, as 6x6x1 * 1x1x1 = 6x6x1
But as the number of filters change, we can control the number of channels!
Such as 28x28x192 * 1x1x192 (32 filters) => 28x28x32
1x1 convolution is also called network in network.
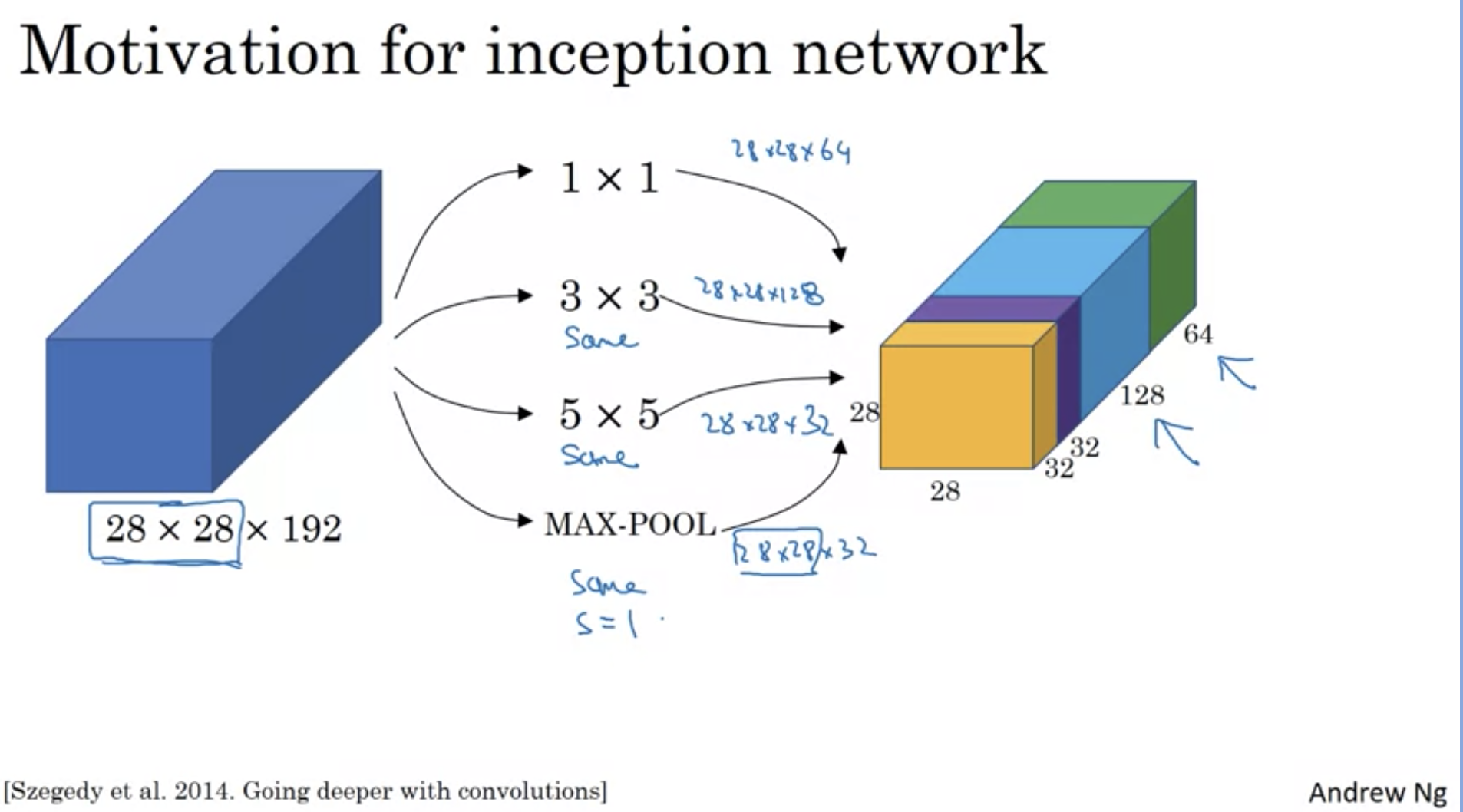
Inception Network Motivation
We can do convolution layer and pooling layer at the same time!
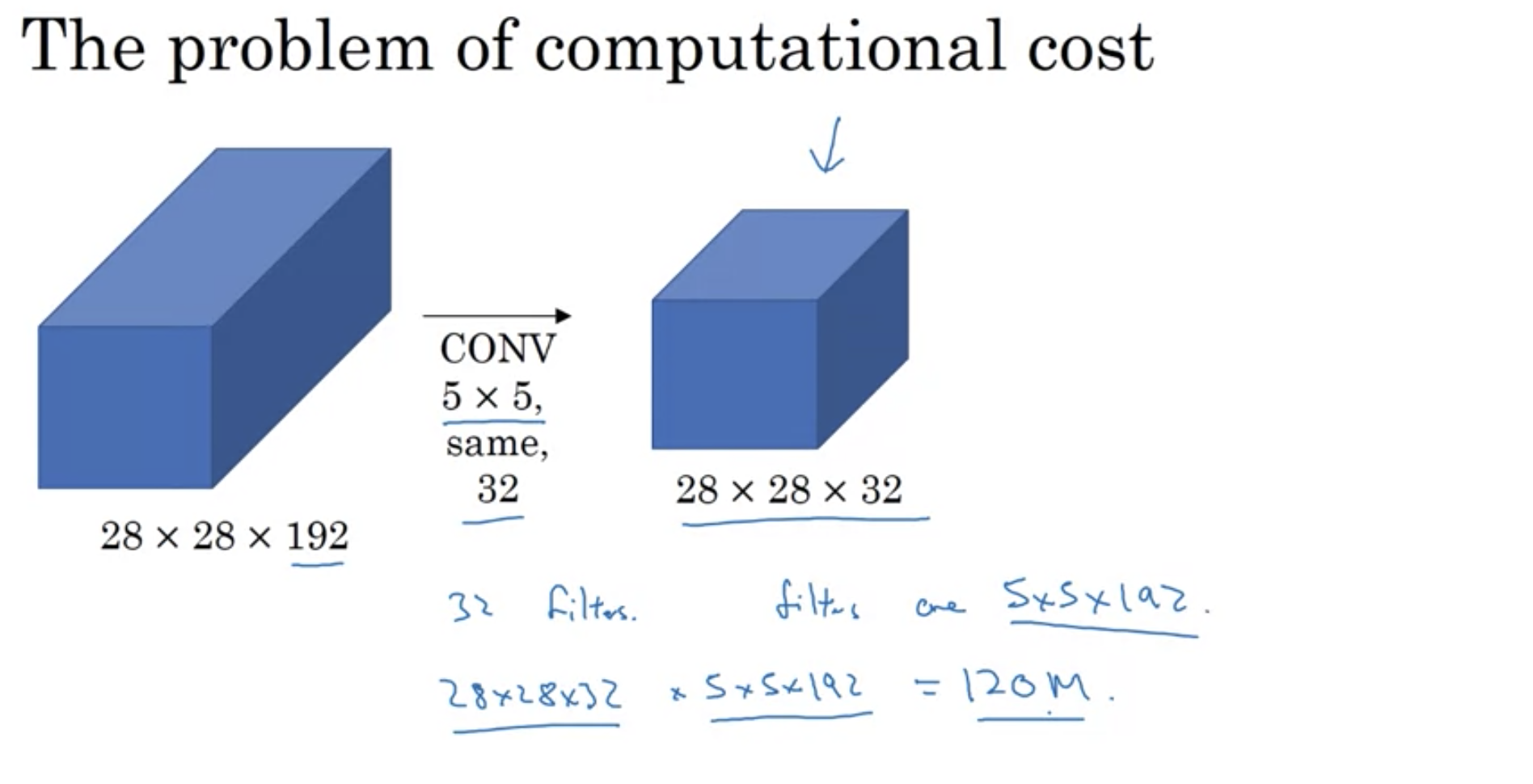
But how about computational Cost?
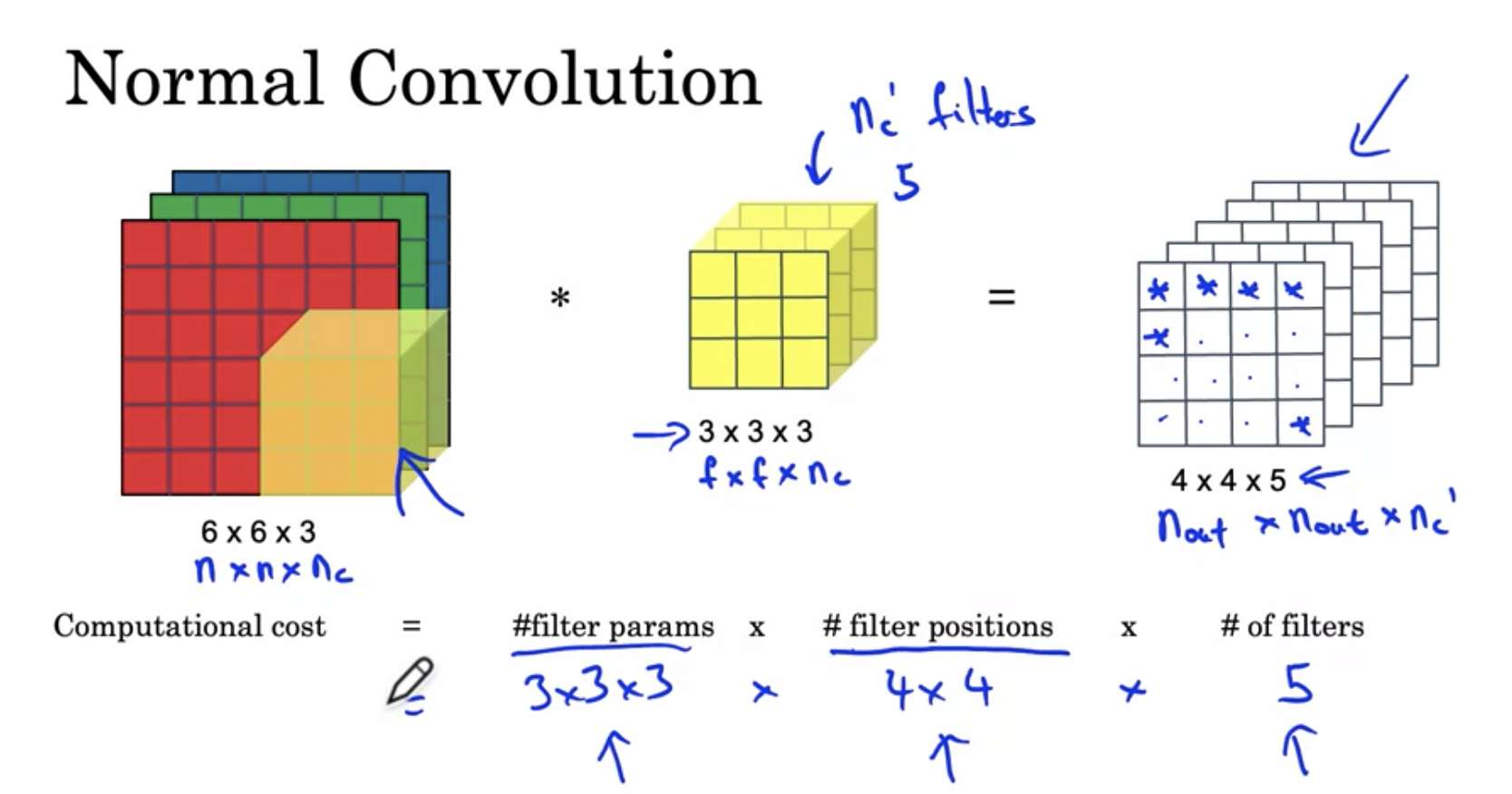
For 28x28x192 and convolution with 5x5x32, we need to do 120 million computations.
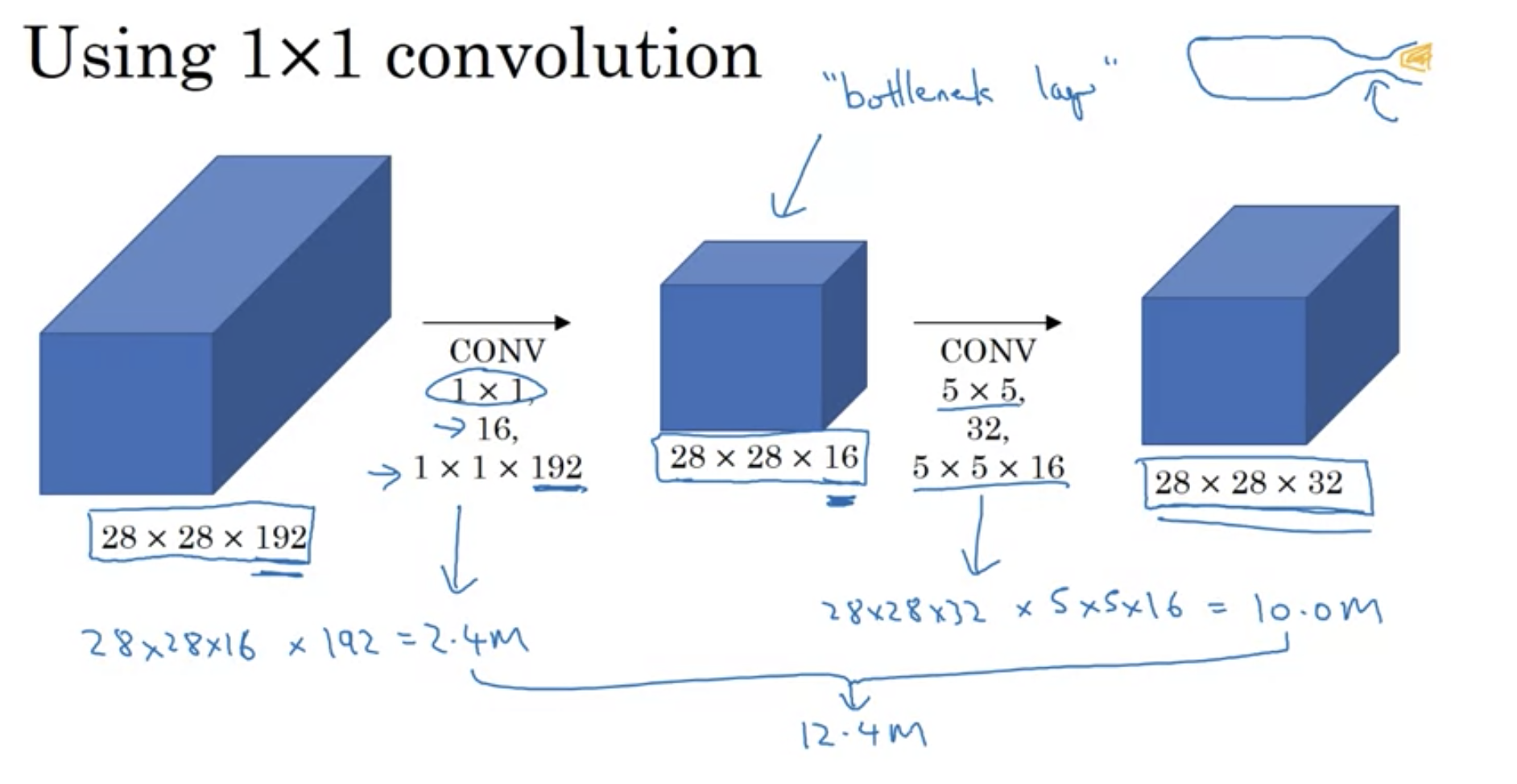
But if we use 1x1 convolution in between, we can reduce the number of computations by 1/10. The 1x1 layer is also called bottleneck layer.
MobileNet Motivation
-
low computational cost at deployment
-
Useful for mobile and embedded vision applications
-
Key idea : Normal vs depthwise - seperable convolutions
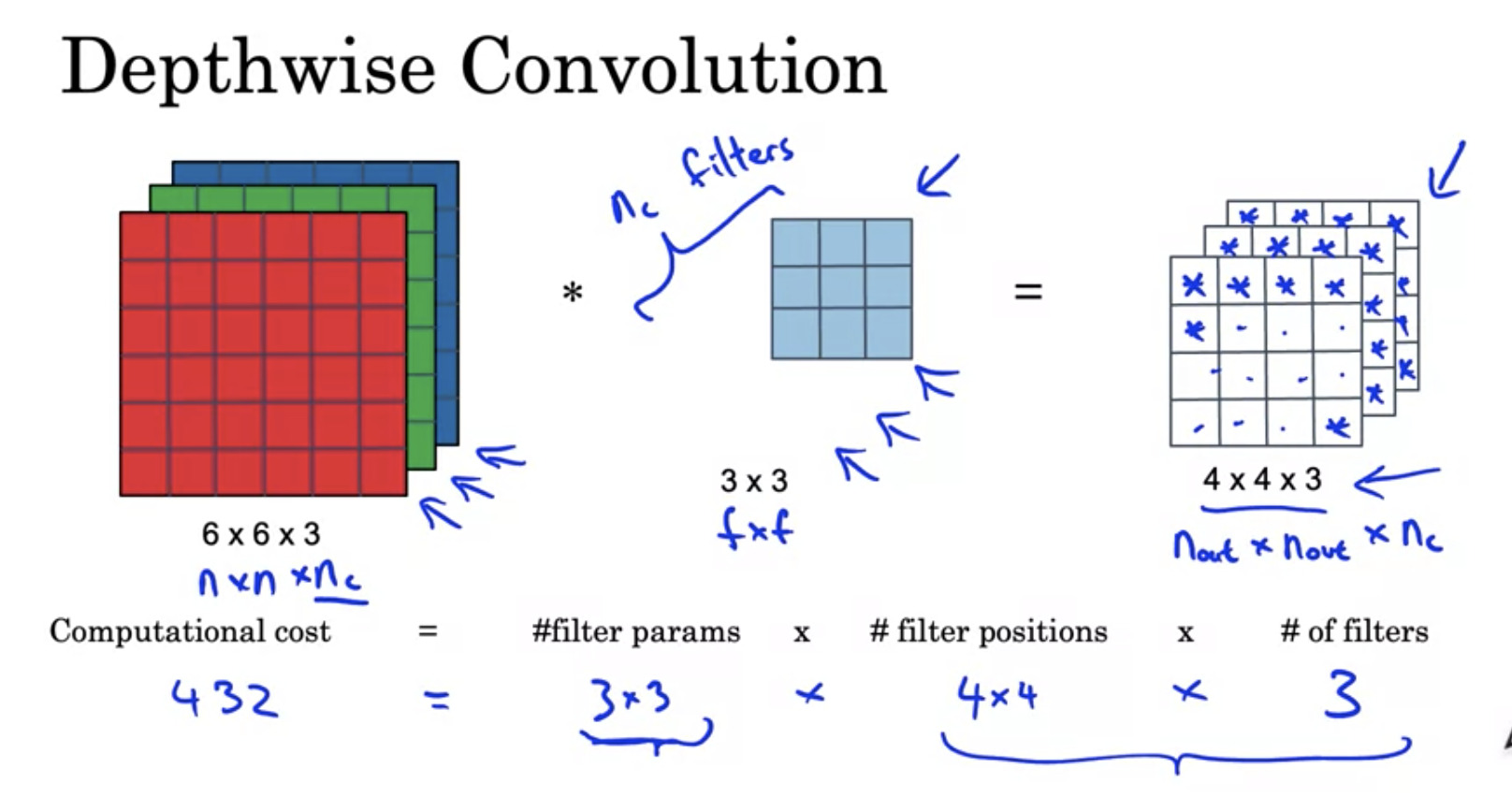
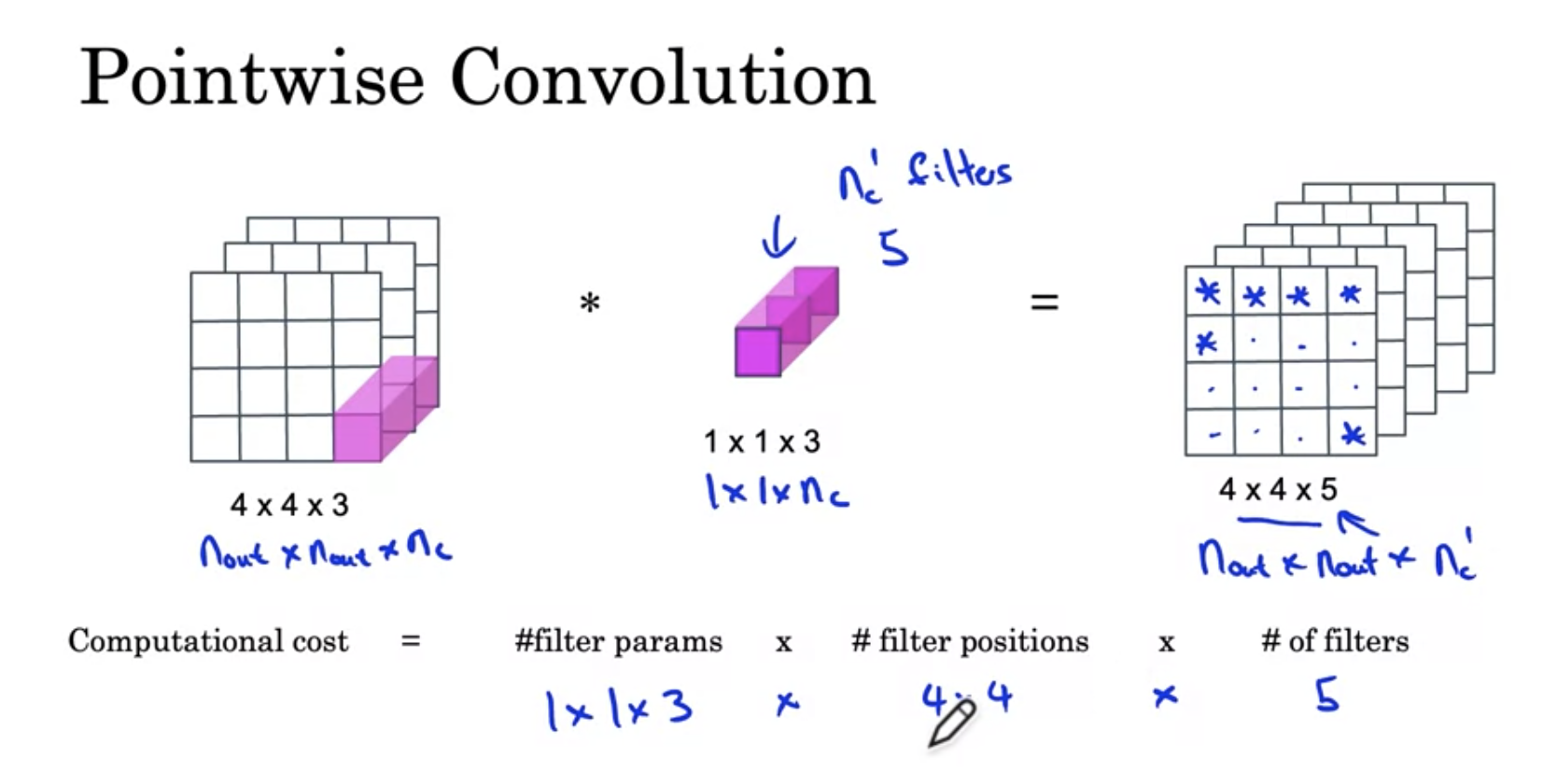

In Summary, Mobilenet makes normal convolution into deptwise separable and pointwise, which uses much less computation.
EfficientNet
We can do three things to scale up/down.
- Use higher resolution (r)
- Use deeper Architecture (d)
- Make the layers wider (w)
EfficientNet helps you to find the best r, d, w for best scaling.
Practical advice for Using Convnets
Transfer Learning is ofter better approach! (pretrained weights)
We can also freeze layers and just train or replace the last layers(softmax)
Also, as usually copmuter vision requires a lot of data, data augmentation is used to fix. (mirroring, random cropping, color shifting) Color distortion, PCA(principle component anlysis)
Other tips - Ensembling, Multi-crop